前言
storm和kafka集群安装是没有必然联系的,我将这两个写在一起,是因为他们都是由zookeeper进行管理的,也都依赖于JDK的环境,为了不重复再写一遍配置,所以我将这两个写在一起。若只需一个,只需挑选自己选择的阅读即可。
这两者的依赖如下:
- Storm集群:JDK1.8 , Zookeeper3.4,Storm1.1.1;
- Kafa集群 : JDK1.8 ,Zookeeper3.4 ,Kafka2.12;
说明: Storm1.0 和Kafka2.0对JDK要求是1.7以上,Zookeeper3.0以上。
下载地址:
Zookeeper:https://zookeeper.apache.org/releases.html#download Storm: http://storm.apache.org/downloads.html Kafka: http://kafka.apache.org/downloadsJDK安装
每台机器都要安装JDK!!!
说明: 一般CentOS自带了openjdk,但是我们这里使用的是oracle的JDK。所以要写卸载openjdk,然后再安装在oracle下载好的JDK。如果已经卸载,可以跳过此步骤。 首先输入 java -version 查看是否安装了JDK,如果安装了,但版本不适合的话,就卸载
输入
rpm -qa | grep java 查看信息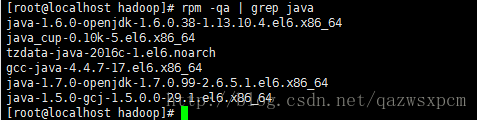 然后输入: rpm -e --nodeps “你要卸载JDK的信息” 如: rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64
然后输入: rpm -e --nodeps “你要卸载JDK的信息” 如: rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64
确认没有了之后,解压下载下来的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz
移动到opt/java文件夹中,没有就新建,然后将文件夹重命名为jdk1.8。
mv jdk1.8.0_144 /opt/javamv jdk1.8.0_144 jdk1.8
然后编辑 profile 文件,添加如下配置
输入:vim /etc/profile
添加:
export JAVA_HOME=/opt/java/jdk1.8export JRE_HOME=/opt/java/jdk1.8/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/libexport PATH=.:${JAVA_HOME}/bin:$PATH 添加成功之后,输入
source /etc/profilejava -version
查看是否配置成功
Zookeeper 环境安装
1,文件准备
将下载下来的Zookeeper 的配置文件进行解压
在linux上输入:tar -xvf zookeeper-3.4.10.tar.gz
然后移动到/opt/zookeeper里面,没有就新建,然后将文件夹重命名为zookeeper3.4
输入mv zookeeper-3.4.10 /opt/zookeepermv zookeeper-3.4.10 zookeeper3.4
2,环境配置
编辑 /etc/profile 文件
输入:export ZK_HOME=/opt/zookeeper/zookeeper3.4 export PATH=.:${JAVA_HOME}/bin:${ZK_HOME}/bin:$PATH 输入:
source /etc/profile
使配置生效
3,修改配置文件
3.3.1 创建文件和目录
在集群的服务器上都创建这些目录
mkdir /opt/zookeeper/data mkdir /opt/zookeeper/dataLog
并且在/opt/zookeeper/data目录下创建myid文件
输入:touch myid
创建成功之后,更改myid文件。
我这边为了方便,将master、slave1、slave2的myid文件内容改为1,2,3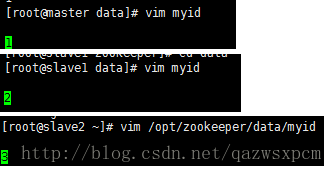
3.3.2 新建zoo.cfg
切换到/opt/zookeeper/zookeeper3.4/conf 目录下
如果没有 zoo.cfg 该文件,就复制zoo_sample.cfg文件并重命名为zoo.cfg。 修改这个新建的zoo.cfg文件dataDir=/opt/zookeeper/datadataLogDir=/opt/zookeeper/dataLogserver.1=master:2888:3888server.2=slave1:2888:3888server.3=slave2:2888:3888
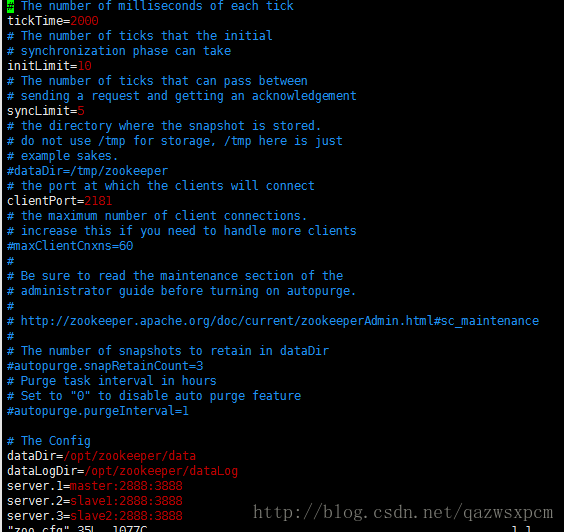
说明:client port,顾名思义,就是客户端连接zookeeper服务的端口。这是一个TCP port。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。dataDir和dataLogDir需要自己创建,目录可以自己制定,对应即可。server.1中的这个1需要和master这个机器上的dataDir目录中的myid文件中的数值对应。server.2中的这个2需要和slave1这个机器上的dataDir目录中的myid文件中的数值对应。server.3中的这个3需要和slave2这个机器上的dataDir目录中的myid文件中的数值对应。当然,数值你可以随便用,只要对应即可。2888和3888的端口号也可以随便用,因为在不同机器上,用成一样也无所谓。
1.tickTime:CS通信心跳数 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。 tickTime=2000 2.initLimit:LF初始通信时限 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。 initLimit=10 3.syncLimit:LF同步通信时限 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。 syncLimit=5依旧将zookeeper传输到其他的机器上,记得更改 /opt/zookeeper/data 下的myid,这个不能一致。
输入:scp -r /opt/zookeeper root@slave1:/optscp -r /opt/zookeeper root@slave2:/opt
4,启动zookeeper
因为zookeeper是选举制,它的主从关系并不是像hadoop那样指定的,具体可以看官方的文档说明。
成功配置zookeeper之后,在每台机器上启动zookeeper。 切换到zookeeper目录下cd /opt/zookeeper/zookeeper3.4/bin
输入:
zkServer.sh start
成功启动之后
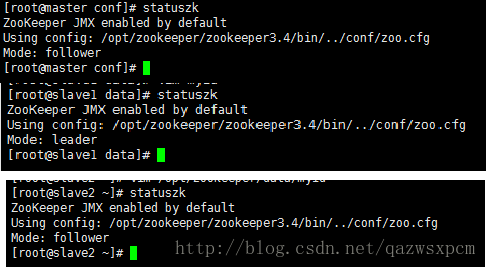
查看状态输入:zkServer.sh status
可以查看各个机器上zookeeper的leader和follower
Storm 环境安装
1,文件准备
将下载下来的storm的配置文件进行解压
在linux上输入:tar -xvf apache-storm-1.1.1.tar.gz
然后移动到/opt/storm里面,没有就新建,然后将文件夹重命名为storm1.1
输入mv apache-storm-1.1.1 /opt/storm mv apache-storm-1.1.1 storm1.1
2,环境配置
编辑 /etc/profile 文件
添加:export STORM_HOME=/opt/storm/storm1.1export PATH=.:${JAVA_HOME}/bin:${ZK_HOME}/bin:${STORM_HOME}/bin:$PATH 输入 storm version 查看版本信息
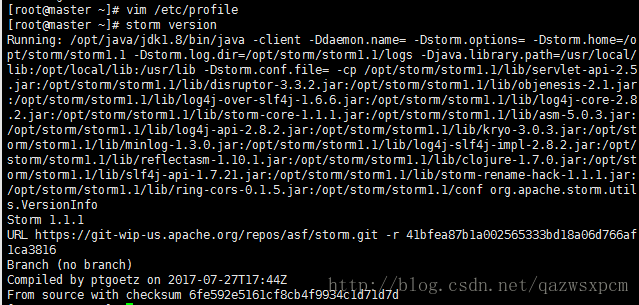
3,修改配置文件
编辑 storm/conf 的 storm.yarm。
进行如下编辑:
输入: vim storm.yarmstorm.zookeeper.servers: - "master" - "slave1" - "slave2"storm.local.dir: "/root/storm"nimbus.seeds: ["master"]supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
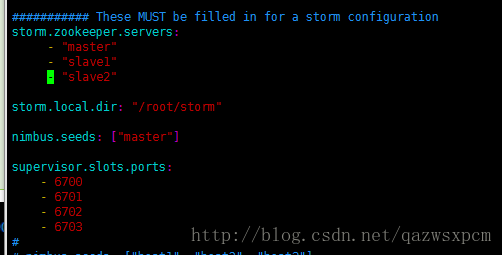
- storm.zookeeper.servers是指定zookeeper的服务地址。 因为storm的存储信息在zookeeper上,所以要配置zookeeper的服务地址。如果zookeeper是单机就只用指定一个!
- storm.local.dir 表示存储目录。 Nimbus和Supervisor守护进程需要在本地磁盘上存储一个目录来存储少量的状态(比如jar,confs等等)。可以在每台机器创建,并给于权限。 3.nimbus.seeds 表示候选的主机。 worker需要知道那一台机器是主机候选(zookeeper集群是选举制),从而可以下载 topology jars 和confs。 4.supervisor.slots.ports 表示worker 端口。 对于每一个supervisor机器,我们可以通过这项来配置运行多少worker在这台机器上。每一个worker使用一个单独的port来接受消息,这个端口同样定义了那些端口是开放使用的。如果你在这里定义了5个端口,就意味着这个supervisor节点上最多可以运行5个worker。如果定义3个端口,则意味着最多可以运行3个worker。在默认情况下(即配置在defaults.yaml中),会有有四个workers运行在 6700, 6701, 6702, and 6703端口。 supervisor并不会在启动时就立即启动这四个worker。而是接受到分配的任务时,才会启动,具体启动几个worker也要根据我们Topology在这个supervisor需要几个worker来确定。如果指定Topology只会由一个worker执行,那么supervisor就启动一个worker,并不会启动所有。
注: 这些配置前面不要有空格!!!,不然会报错。 这里使用的是主机名(做了映射),也可以使用IP。实际的以自己的为准。
可以使用scp命令或者ftp软件将storm复制到其他机器上

成功配置之后,然后就可以启动Storm了,不过要确保JDK、Zookeeper已经正确安装,并且Zookeeper已经成功启动。
4,启动Storm
切换到 storm/bin 目录下
在主节点(master)启动输入:storm nimbus >/dev/null 2>&1 &
访问web界面(master)输入:
storm ui
从节点(slave1,slave2)输入:
storm supervisor >/dev/null 2>&1 &
在浏览器界面输入: 8080端口
成功打开该界面,表示环境配置成功: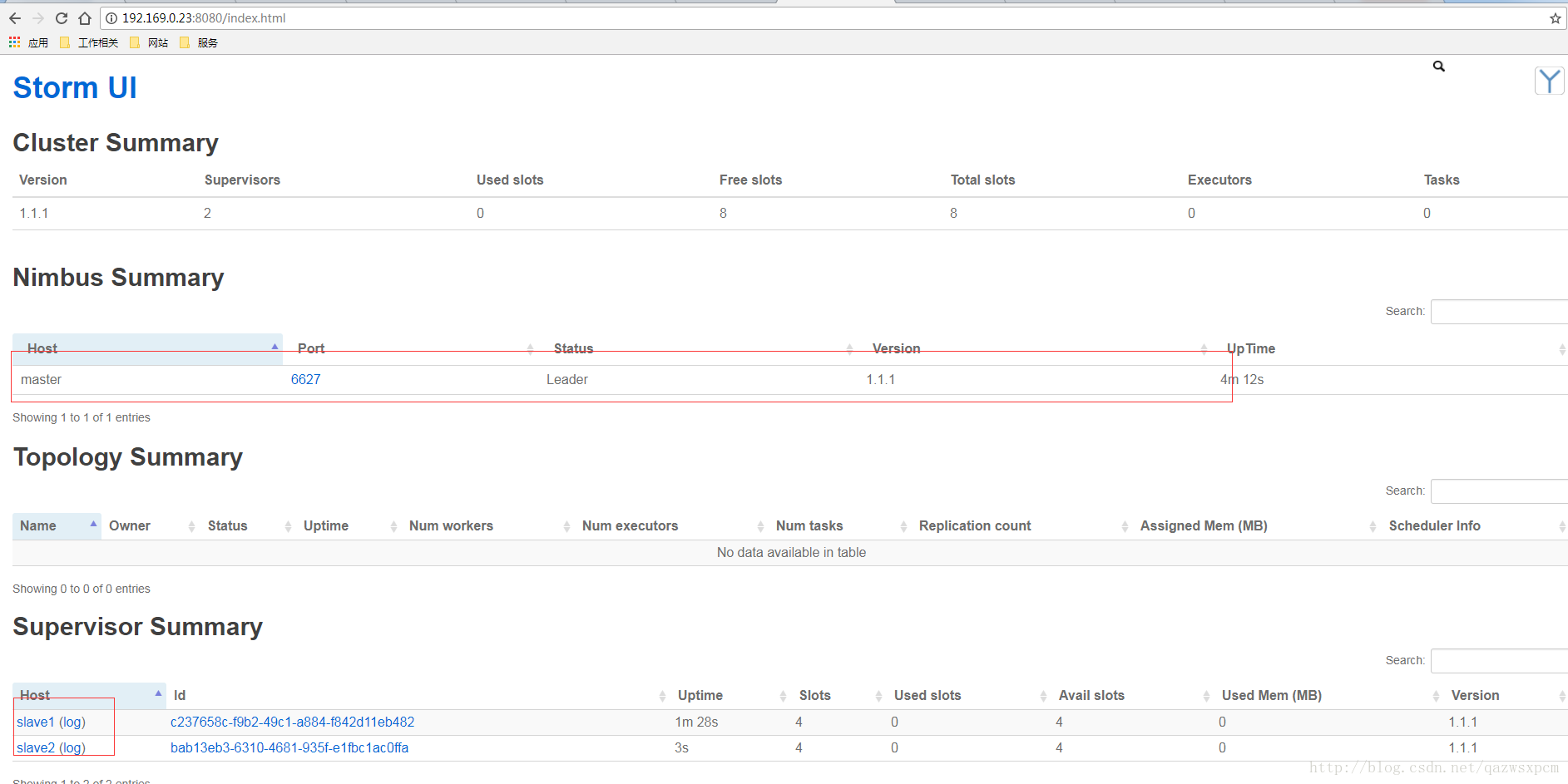
kafka的环境安装
1,文件准备
将下载下来的Kafka的配置文件进行解压
在linux上输入:tar -xvf kafka_2.12-1.0.0.tgz
然后移动到/opt/kafka里面,没有就新建,然后将文件夹重命名为kafka2.12
输入mv kafka_2.12-1.0.0 /opt/kafka mv kafka_2.12-1.0.0 kafka2.12
2,环境配置
编辑 /etc/profile 文件
输入:export KAFKA_HOME=/opt/kafka/kafka2.12 export PATH=.:${JAVA_HOME}/bin:${KAFKA_HOME}/bin:${ZK_HOME}/bin:$PATH 输入:
source /etc/profile
使配置生效
3,修改配置文件
注:其实要说的话,如果是单机的话,kafka的配置文件可以不用修改,直接到bin目录下启动就可以了。但是我们这里是集群,所以稍微改下就可以了。
切换到kafka/config 目录下
编辑server.properties 文件 需要更改的是Zookeeper的地址: 找到Zookeeper的配置,指定Zookeeper集群的地址,设置如下修改就可以了zookeeper.connect=master:2181,slave1:2181,slave2:2181zookeeper.connection.timeout.ms=6000
其它可以选择更改的有
1 ,num.partitions 表示指定的分区,默认为1
2,log.dirs kafka的日志路径,这个按照个人需求更改就行3, broker.id:非负整数,用于唯一标识broker,每台不一样...
注:还有其它的配置,可以查看官方文档,如果没有特别要求,使用默认的就可以了。配置好之后,记得使用scp 命令传输到其它的集群上,记得更改server.properties 文件!
4,启动kafka
集群每台集群都需要操作!
切换到kafka/bin 目录下
输入:kafka-server-start.sh
然后输入jps名称查看是否成功启动:
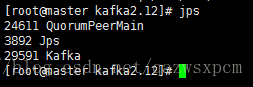
成功启动之后,可以进行简单的测试下
首先创建个topic 输入:kafka-topics.sh --zookeeper master:2181 --create --topic t_test --partitions 5 --replication-factor 2
说明: 这里是创建了一个名为 t_test 的topic,并且指定了5个分区,每个分区指定了2个副本数。如果不指定分区,默认的分区就是配置文件配置的。
然后进行生产数据
输入:kafka-console-producer.sh --broker-list master:9092 --topic t_test

可以使用进行Ctrl+D 退出
然后我们再打开一个xshell窗口
进行消费 输入:kafka-console-consumer.sh --zookeeper master:2181 --topic t_test --from-beginning

可以看到数据已经正常消费了。
5,kafka的一些常用命令
1.启动和关闭kafka
bin/kafka-server-start.sh config/server.properties >>/dev/null 2>&1 &bin/kafka-server-stop.sh
2.查看kafka集群中的消息队列和具体队列
查看集群所有的topickafka-topics.sh --zookeeper master:2181,slave1:2181,slave2:2181 --list
查看一个topic的信息
kafka-topics.sh --zookeeper master:2181 --describe --topic t_test
3.创建Topic
kafka-topics.sh --zookeeper master:2181 --create --topic t_test --partitions 5 --replication-factor 2
4.生产数据和消费数据
kafka-console-producer.sh --broker-list master:9092 --topic t_test
Ctrl+D 退出
kafka-console-consumer.sh --zookeeper master:2181 --topic t_test --from-beginning
Ctrl+C 退出
5.kafka的删除命令
kafka-topics.sh --delete --zookeeper master:2181 --topic t_test
6,添加分区
kafka-topics.sh --alter --topict_test --zookeeper master:2181 --partitions 10
其它
Storm环境搭建参考官方文档:
http://storm.apache.org/releases/1.1.1/Setting-up-a-Storm-cluster.htmlKafka环境搭建参考官方文档:
http://kafka.apache.org/quickstart到此,本文结束,谢谢阅读!